Build Your Own GitHub Copilot
GitHub Copilot, Cursor, Windsurf, Cline, Aider, the list goes on. AI-powered coding assistants have established themselves as indispensable tools in software developers' tool-kits in 2025, and for good reason - they undoubtedly make you faster and more productive while writing code. I'm thankful for AI code completions every time I need to write boilerplate, implement repetitive logic, or write short functions and utilities.
But for all their prowess and intelligence, they can still fail catastrophically when faced with their ultimate arch nemesis: Enterprise Code™ - characterized by complex business logic, institutional knowledge spread across teams, legacy systems and APIs with varying levels of documentation.

LLMs often hallucinate when dealing with complex, esoteric code with limited context, through no fault of their own. They simply haven't been trained on your codebase to know enough about it to offer useful intelligence.
And then there's the other issue: big enterprise is often wary of tools (Copilot et al.) that siphon off the entire repository to external servers just for serving autocomplete suggestions.
Thankfully, there's a solution to both of these problems: open-weight models.
In theory, we should be able to take the best open-weight coding models, fine-tune them to our specific code repositories, and deploy them privately to get the same (or better) experience offered by these coding copilots - at a fraction of the cost.
This is what I set out to explore and answer in this blog post: what kind of performance improvements can we expect from models fine-tuned to a single code repository?
The Experiment
Here's the plan:
- Take the best open-model that I can run and fine-tune on my GPU (RTX 4090, 24 GB VRAM).
- Pick a code repo that uses a relatively niche framework where the mainstream LLMs don't fare well.
- Generate a fill-in-the-middle (FIM) dataset from the code in the repo.
- Evaluate the out-of-the-box model to get a baseline.
- Run supervised fine-tuning (SFT) on the dataset.
- Evaluate once again and compare against the baseline.
I. Choosing a Model
Open-source models have gotten really good. Qwen 2.5 Coder claims to beat most other coding models at almost all benchmarks (https://qwenlm.github.io/blog/qwen2.5-coder-family/) so it's a safe choice for this experiment.
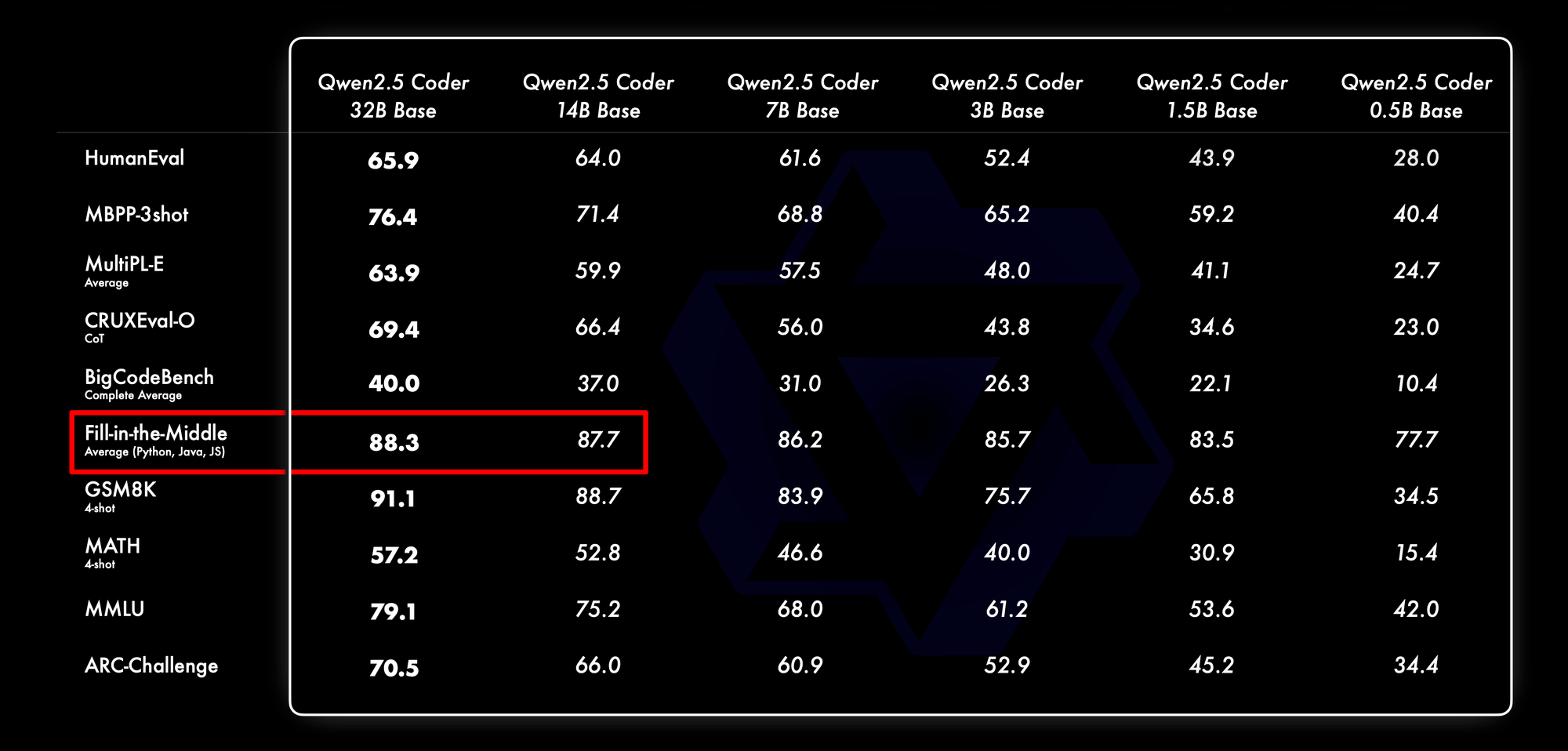
Since I have only 24 GB to run and train my model, I had to settle for the 14B, 4-bit quantized version of the model: unsloth/Qwen2.5-Coder-14B-bnb-4bit. Because we're only concerned about FIM performance, we're not losing much since the 14B version scores only 0.6% below the 33B model:
II. The Code
LLMs do fairly well when dealing with popular languages (Java, Python, C++), libraries and frameworks. One framework where I've personally found LLMs to not work as great is the frontend framework Svelte, and that's what I decided to work with. I went hunting for a suitable repo, and found this fairly large codebase written in Svelte and TypeScript: https://github.com/hcengineering/platform.
Some basic stats:
| File Type | Number of Files | Total Lines of Code |
|---|---|---|
| Svelte (*.svelte) | 1978 | 24,721 |
| TypeScript (*.ts) | 1827 | 277,651 |
That should be enough code to run a modest fine-tuning experiment. The next step is generating a FIM dataset for our LLM to train on.
III. The FIM Task
Code auto-completion can be modeled as a FIM (fill-in-the-middle) task; where you make LLMs, well, fill in the middle. You prompt the model with the prefix and suffix, and hope that the LLM will generate the correct middle portion to connect the two.
As a concrete example, consider this random block of code:
function updateCurrentProjectPref(currProject: Project) {
const prefs = await client.findOne()
// Caret here
|
}
If we wanted our model to generate completions at the caret position above, we would prompt it like so:
<|fim_prefix|>
function updateCurrentProjectPref(currProject: Project) {
const prefs = await client.findOne()
<|fim_suffix|>
}
<|fim_middle|>
The LLM will then generate tokens beyond the <|fim_middle|> token to complete the middle. So for our fine-tuning task, we need to generate samples like these from our code.
There are several ways to do this. For this experiment, we'll try a very basic file-level sample generation. For each source file, we will generate multiple samples by masking out "critical" code blocks:
- Control flow blocks (if-else, each, await)
- Function definitions
- Imports
- Variable declarations
We parse source files using the svelte compiler and identify relevant nodes in the AST to mask out. This should mimic the scenarios encountered while writing code, at least to some extent.
With our chosen codebase, we generate the following train and test sets:
# Number of samples in each set
❯ wc -l dataset.train.jsonl
43733 dataset.train.jsonl
❯ wc -l dataset.test.jsonl
1149 dataset.test.jsonl
# Number of unique files in each set
❯ jq '.filePath' dataset.train.jsonl | sort | uniq | wc -l
1836
❯ jq '.filePath' dataset.test.jsonl | sort | uniq | wc -l
35
The test split comes from a random 2% holdout sample of all files in the repo, meaning the model doesn't see any code from the test files during training.
I initially wanted to generate samples from both .svelte and .ts files. But that would require implementing a separate AST parser for TS files, and since I wanted some quick results, I decided to go ahead with only Svelte files first.
IV. Baseline Performance
There are several ways to evaluate whether a given completion is valid or not. Ordered from most accurate to least:
- Build the project and run unit tests
- Syntax-based comparison against ground truth
- Exact match
- Some similarity score (e.g., BLEU)
A more rigorous experiment would use 1 or 2; but for our purposes, the latter two will be sufficient to give us a sense of whether fine-tuning helps or not, and to what degree.
With our chosen model unsloth/Qwen2.5-Coder-14B-bnb-4bit, we get our baseline:
❯ python metrics.py generated.test.jsonl
Total: 1149
Exact Matches: 283
[Exact Match] Accuracy: 0.25
BLEU Score: 0.2243
Not too shabby! The out-of-the-box model gives us exact completions 25% of the time. This number underestimates the actual performance of the model, since quite often there's more than one correct completion in a given context. A better estimate can be obtained by actually building the code to check for syntactic and semantic correctness, but evidently I am too lazy to implement it.
Can we do better with some fine-tuning? Let's find out.
V. Training
We run LoRA (Low-Rank Adaptation) training via unsloth with rank 16, for a total of ~68M trainable parameters. With a sequence length of 4096, batch size of 2, gradient accumulation steps of 4, I could only manage a measly 0.1 iter/sec on my RTX 4090. This meant that a full training run (~5400 steps) would take 15-16 hours! (H100 would give you an easy 5-10x improvement on this, so it should take much less time with capable hardware.)
I kicked off the training run at night, hoping to see results the next morning; but Bangalore's infamous power grid had other ideas. A voltage fluctuation incident cut short the training run - a lot shorter than I would have liked - after only 900 iterations. And since I had check-pointing enabled only every 500 steps, at the end I only had checkpoint #500 to work with.
VI. Evaluation
Since the trained model only saw around 10% of the training set, I had fairly tepid expectations of this checkpoint. After all, it had probably seen samples from only around 200 out of the ~2000 Svelte source files in the project. But I decided to see how far it had gotten nonetheless:
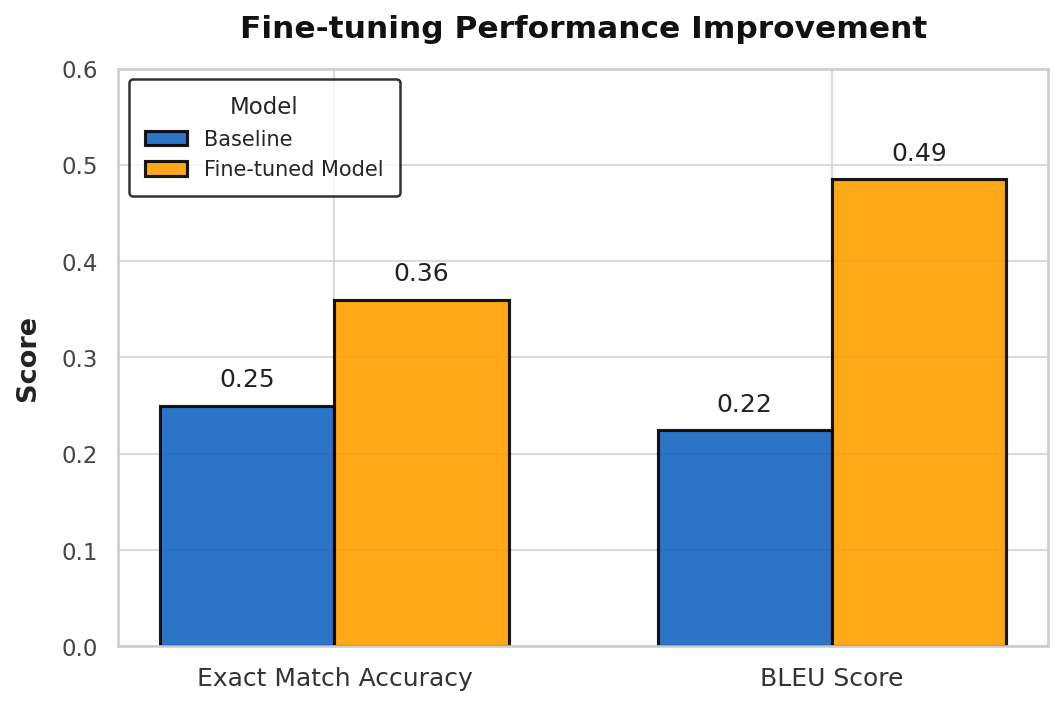
❯ python metrics.py generated-post-finetune.test.jsonl
Total: 1149
Exact Matches: 416
[Exact Match] Accuracy: 0.36
BLEU Score: 0.4851
# Baseline metrics, reproduced from above
❯ python metrics.py generated.test.jsonl
Total: 1149
Exact Matches: 283
[Exact Match] Accuracy: 0.25
BLEU Score: 0.2243
A 47% improvement on exact match! BLEU has more than doubled. This means that the model is now producing code that is much closer to existing code in the repository.
The fact that we see such significant uplifts in performance from such a short training run tells me that there's a lot of room for improvement, which will be interesting to explore in future blog posts. Stay tuned!
(See the appendix below for samples of completions generated by both the baseline and the fine-tuned model.)
Conclusion and Future Work
The results of this limited scale experiment are quite promising. It shows that there are a lot of gains to be had by fine-tuning to a specific codebase, making fine-tuned open-weight models a great choice for building code completion systems, especially for organizations that have reservations about exposing their code to an external API.
With access to more compute, we can run a larger scale experiment with the larger models (e.g., Qwen 2.5 Coder 32B) and train them with longer sequence lengths. This should give us performance on par with the best coding assistants out there, potentially even exceeding them.
There are several directions for exploring and building on this further:
- How does this compare to an effective RAG implementation (based on actual dependencies between source files)
- Compare against existing code completion models. (A little difficult to do because each assistant has its own way of packing the repository context in the prompt.)
- Investigate over-fitting on the fine-tune dataset, i.e., ensure that the model does not forget prior knowledge.
- Keeping the model up-to-date as new commits land on a real production source repo.
Links
- Code: https://github.com/prvnsmpth/finetune-code-assistant.
- The WandB training run: https://wandb.ai/casepro/huggingface/runs/b904bkvj/workspace?nw=nwuserprvnsmpth (edit: the link is not accessible, because apparently public sharing is premium feature on WandB ¯\_(ツ)_/¯. Trying to find a workaround.)
Appendix: A Closer Look
Metrics aside, I think it's quite instructive to closely examine a few randomly picked examples:
Example #1
| 1 | function getIssueTemplateId (currentProject: Project | undefined, issue: IssueTemplateChild): string { |
| 2 | return currentProject !== undefined |
| 3 | ? `${currentProject.identifier}-${issues.findIndex((it) => it.id === issue.id)}` |
| 4 | : `${issues.findIndex((it) => it.id === issue.id)}}` |
| 2 | if (currentProject?.type === tracker.ProjectType.IssueTemplate) { |
| 3 | return `${issue.id}` |
| 4 | } |
| 5 | return `${issue.id}` |
| 2 | if (currentProject === undefined) return '' |
| 3 | const prefix = currentProject?.identifier.toUpperCase() ?? '' |
| 4 | return `${prefix}-${issue.issueIdentifier}` |
| 5 | } |
Here's a failure case where the fine-tuned model doesn't get the right completion, but still gets close to it. The baseline gets it completely wrong, assuming issue ID can be used as issue template ID. The fine-tuned model gets somewhat close, it correctly predicts that the current project ID should be used as a prefix. Interesting.
Example #2
| 1 | |
| 2 | function addRelation (): void { |
| 3 | showPopup(CreateRelation, { |
| 4 | aClass: masterTag._id |
| 5 | }) |
| 6 | } |
| 2 | const addRelation = (): void => { |
| 3 | showPopup({ |
| 4 | component: CreateRelation, |
| 5 | props: { |
| 6 | masterTag: masterTag |
| 7 | } |
| 8 | }) |
| 9 | } |
| 2 | function addRelation (): void { |
| 3 | showPopup(CreateRelation, { masterTag }, 'top') |
| 4 | } |
| 10 |
Once again, while the completion from the fine-tuned model isn't exactly right, it gets closer to the expected function definition than the baseline.
Example #3
| 1 | const selectedDoneStates: Set<Ref<Status>> = new Set<Ref<Status>>() |
| 2 | $: resConfig = updateConfig(config) |
| 3 | |
| 4 | $: doneStates = getStates(_space, $typeStore, $statusStore.byId).filter( |
| 5 | (p) => p.category && [task.statusCategory.Won, task.statusCategory.Lost].includes(p.category) |
| 6 | ) |
| 4 | let resConfig: string[] = [] |
| 5 | const doneStates = getStates(_space, task.statusCategory.Done) |
| 4 | const doneStates = $statusStore.filter((p) => p.category === task.statusCategory.Done) |
| 7 | |
| 8 | $: itemsDS = getItems(doneStates) |
| 9 | let selectedDS: string[] = [] |
Here both the baseline and the fine-tuned completion are off-the-mark by quite a bit, but the fine-tuned version correctly predicts that it needs to use the information from the $statusStore store to determine the done states. But it incorrectly assumes that the Done category is all you need to check for.
Example #4
| 1 | } |
| 2 | |
| 3 | |
| 4 | function noDoneClick (): void { |
| 5 | withoutDone = true |
| 6 | selectedDS = ['NoDoneState'] |
| 7 | selectedDoneStates.clear() |
| 8 | updateQuery(query, selectedDoneStates) |
| 9 | } |
| 4 | function noDoneClick (): void { |
| 5 | if (selectedDS.length === 1 && selectedDS.includes('NoDoneState')) { |
| 6 | selectedDS = [] |
| 7 | withoutDone = false |
| 8 | } else { |
| 9 | selectedDS = ['NoDoneState'] |
| 10 | withoutDone = true |
| 11 | } |
| 12 | updateQuery(query, selectedDoneStates) |
| 13 | } |
| 14 | |
| 15 | let resConfig: string[] = [] |
| 16 | let doneStates: Status[] = [] |
| 17 | let itemsDS: TabItem[] = [] |
| 18 | let $typeStore = $typeStore |
| 19 | let $statusStore = $statusStore |
| 4 | function noDoneClick (): void { |
| 5 | withoutDone = true |
| 6 | selectedDoneStates.clear() |
| 7 | updateQuery(query, selectedDoneStates) |
| 8 | } |
| 20 | |
| 21 | |
| 22 | $: updateQuery(query, selectedDoneStates) |
The fine-tuned version gets quite close!
Example #5
| 1 | export let field: BitrixFieldMapping | undefined |
| 2 | |
| 3 | |
| 4 | let findField: string = (field?.operation as FindReferenceOperation)?.field ?? '' |
| 4 | let findField = (field?.operation as FindReferenceOperation)?.field ?? '' |
| 5 | let items: DropdownTextItem[] = [] |
| 4 | let findField = (field?.operation as FindReferenceOperation)?.field ?? '' |
| 6 | |
| 7 | let referenceType = (field?.operation as FindReferenceOperation)?.referenceType ?? BitrixEntityType.Company |
| 8 | let referenceClass = (field?.operation as FindReferenceOperation)?.referenceClass ?? core.class.Doc |
The baseline almost gets it right, but hallucinates an extra items variable for some reason. The fine-tuned version is exactly right. (Although this won't count as an exact match because of the missing TypeScript type annotation.)
Example #6
| 1 | |
| 2 | const dispatch = createEventDispatcher() |
| 3 | |
| 4 | const client = getClient() |
| 4 | const client = getClient() |
| 5 | let icon: testManagement.icon.TestCaseStatusIcon |
| 6 | let label: testManagement.string.TestCaseStatusLabel |
| 7 | let itemsInfo: { id: TestCase['status']; isSelected: boolean; icon: testManagement.icon.TestCaseStatusIcon; label: testManagement.string.TestCaseStatusLabel }[] |
| 4 | const client = getClient() |
| 8 | |
| 9 | |
| 10 | $: itemsInfo = defaultTestCaseStatuses.map((status) => ({ |
The baseline hallucinates unnecessary variables.
Example #7
| 1 | import { Document } from '@hcengineering/controlled-documents' |
| 2 | import { getClient } from '@hcengineering/presentation' |
| 3 | |
| 4 | import { EditBox } from '@hcengineering/ui' |
| 5 | import view from '@hcengineering/view' |
| 6 | |
| 7 | import plugin from '../../../plugin' |
| 4 | import { getMetadata } from '@hcengineering/platform' |
| 5 | import { view } from '@hcengineering/ui' |
| 6 | import { EditBox } from '@hcengineering/view' |
| 7 | import { plugin } from './plugin' |
| 8 | |
| 9 | export let abstract = '' |
| 4 | import { EditBox } from '@hcengineering/ui' |
| 5 | import { view } from '@hcengineering/view' |
| 6 | import { createEventDispatcher } from 'svelte' |
| 7 | import plugin from '../../../plugin' |
| 10 | |
| 11 | |
| 12 | export let value: Document | undefined |
The fine-tuned model gets the imports right. It has learnt that EditBox comes from @hcengineering/ui and not @hcengineering/view.
Example #8
| 1 | } |
| 2 | |
| 3 | async function changeStatus (newStatus: TestCase['status'] | null | undefined): Promise<void> |
| 4 | { |
| 5 | if (disabled || newStatus == null || value === newStatus) { |
| 6 | return |
| 7 | } |
| 8 | |
| 9 | value = newStatus |
| 10 | dispatch('change', value) |
| 11 | |
| 12 | if ('_id' in object) { |
| 13 | await client.update(object, { status: newStatus }) |
| 14 | } |
| 15 | } |
| 4 | { |
| 5 | if (newStatus !== null && newStatus !== undefined) { |
| 6 | value = newStatus |
| 7 | await client.update(object, { status: newStatus }) |
| 8 | dispatch('change', { value: newStatus }) |
| 9 | } |
| 10 | } |
| 4 | { |
| 5 | if (disabled || newStatus == null || newStatus === value) { |
| 6 | return |
| 7 | } |
| 8 | |
| 9 | value = newStatus |
| 10 | dispatch('change', value) |
| 11 | |
| 12 | if ('_class' in object) { |
| 13 | await client.update(object, { status: newStatus }) |
| 14 | } |
| 15 | } |
| 16 | |
| 17 | |
| 18 | $: icon = value === undefined ? testManagement.icon.StatusDraft : testCaseStatusAssets[value].icon |
The baseline gets pretty close! Just one token off.
These examples reveal a lot about how the fine-tuned model has gleaned patterns specific to this repo. A full fine-tuning run will quite likely result in a much better model.