Hosting Your Own Coding LLM
What does it take to deploy your own, private LLM? What kind of resources do you need? And how much does it cost? We'll try and answer some of these questions in this post, in the context of one specific use-case: code completion.
Tl;dr
Price to performance plot of three different models running Qwen 2.5 Coder 7B, handling a workload of 32 code completion req/sec:
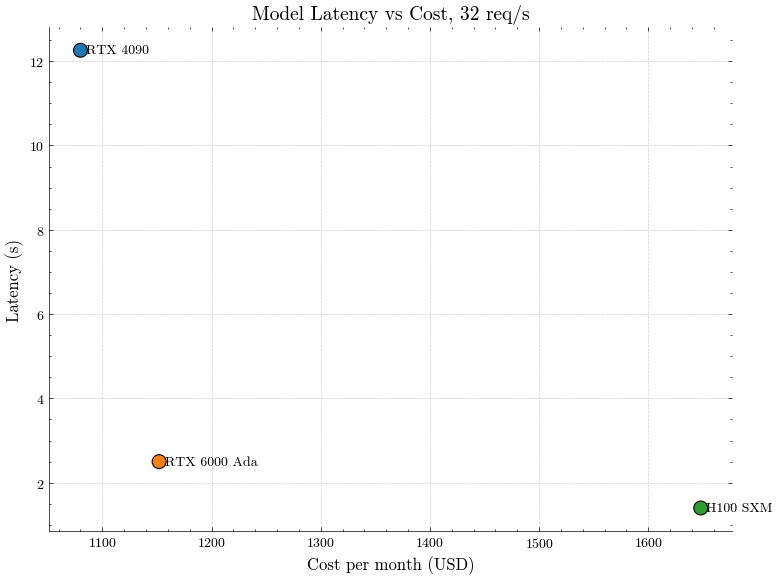
On the Y-axis, latency is the time to receive a full response (128 tokens). On the X-axis, we have the approx. monthly cost to run a GPU instance to support the workload.
The Most Important Metric: Latency
The #1 performance metric for a coding assistant LLM is latency. Developers hate tools that are slow to respond while coding.
There are several considerations for an LLM inference system that will influence latency:
- The context length (i.e., number of tokens sent and received)
- The model size (i.e., number of parameters)
- Memory bandwidth
- Total VRAM available
- Whether or not you are dynamically loading LoRA adapters per request
- And more...
We'll evaluate a few combinations of the above and see how it impacts latency. We'll use vLLM for running model inference, and vegeta to generate load, capture metrics and plot them.
Before we jump into computing latency, let's get an estimate for the workload.
Estimating peak QPS
Let's say we have a team of 100 developers, all working the same hours, in the same timezone. Let's assume that during peak coding hours, a developer makes one completion request every 5 seconds. So,
\[\text{Average QPS} = 100 \times \frac{1}{5} = 20 \text{ QPS}\]
Assuming requests are independently and randomly distributed over time, the number of requests in a given second follows a Poisson distribution:
\[X \sim \text{Poisson}(\lambda = 20)\]
The standard deviation for this distribution:
\[\text{Standard Deviation} = \sqrt{\lambda} = \sqrt{20} \approx 4.47\]
To estimate peak QPS, we look at a high percentile (e.g., the 99.9th percentile) of the Poisson distribution.
For a Poisson distribution with \(\lambda = 20\), the 99.9th percentile can be computed using a normal approximation:
\[\text{Peak QPS} \approx \lambda + 3\sigma = 20 + (3 \times 4.47) \approx 33.4\]
So, for a team of 100 developers, we need to be able to handle about 33 req/sec at peak. Let's make that a nice, round number: 32 req/sec.
The Benchmark Setup
Model context length: We'll limit the max context length to 4096 tokens. In practice, this is more than enough context to provide useful completions. Longer context windows will degrade response times because of longer prompt processing times.
Output tokens: We'll set max output tokens to 128. For reference, this is what 128 tokens of code looks like:
if (this->state->link_state == LinkState_Closing) {
prv_transition_to(this, LinkState_Closed);
} else if (this->state->link_state == LinkState_Stopping) {
prv_transition_to(this, LinkState_Stopped);
} else if (this->state->link_state == LinkState_AckReceived) {
prv_transition_to(this, LinkState_RequestSent);
} else if (this->state->link_state == LinkState_Opened) {
PBL_LOG(LOG_LEVEL_WARNING, "Terminate-Ack received on an open connection");
}The request: We will send a request payload with a ~700 token prompt. A bit shorter than regular completion requests, but since latency is dominated by the number of output tokens, the results should still be representative.
Humble Beginnings: 7B model on an RTX 4090 (24 GB)
We'll start simple: a single instance of a 7B parameter model, deployed on a single GPU node.
Model: Qwen/Qwen2.5-Coder-7B
GPU: A single RTX 4090, 24 GB VRAM
We'll run a sustained load test at 32 req/sec for a duration of 5s. Performance at this QPS is expected to be atrocious because after the ~20G or so used up by the model weights and KV cache, there's barely any room for a batch size of 8, let alone 32. But we'll try anyway:
(All latency numbers are for receiving the full-response, and not just time-to-first-token.)
❯ echo "POST http://localhost:8080/v1/completions" | vegeta attack -rate=32 -duration=5s -body req.json -header 'Content-Type: application/json' | tee 4090/results.8.bin | vegeta report
Requests [total, rate, throughput] 160, 32.20, 9.86
Duration [total, attack, wait] 16.229s, 4.969s, 11.26s
Latencies [min, mean, 50, 90, 95, 99, max] 7.174s, 9.729s, 9.657s, 11.838s, 12.063s, 12.258s, 12.291s
Bytes In [total, mean] 144460, 902.88
Bytes Out [total, mean] 466240, 2914.00
Success [ratio] 100.00%
Status Codes [code:count] 200:160
Error Set:As pathetic as expected – p99 latency of 12s. So what's the best we can do with a 4090?
Let's try dropping down to 8 req/sec:
❯ echo "POST http://localhost:8080/v1/completions" | vegeta attack -rate=8 -duration=5s -body req.json -header 'Content-Type: application/json' | tee 4090/results.8.bin | vegeta report
Requests [total, rate, throughput] 40, 8.20, 5.44
Duration [total, attack, wait] 7.359s, 4.876s, 2.484s
Latencies [min, mean, 50, 90, 95, 99, max] 2.484s, 3.784s, 3.855s, 4.693s, 4.731s, 4.758s, 4.758s
Bytes In [total, mean] 36087, 902.17
Bytes Out [total, mean] 116560, 2914.00
Success [ratio] 100.00%
Status Codes [code:count] 200:40
Error Set:Much better, but still not quite practically usable. 4.7 seconds is an eternity while writing code, you'll be done writing the code by yourself before you even see the suggestion appear. Token throughput: \(\frac {\text{40 requests} \times \text{128 tok/req}} {\text{7.3s}} \approx \text{700 output tok/sec}\).
At this level of performance, to support our stated goal of 32 req/sec, we'd need:
- Hardware: 4x RTX 4090
- Cost: $1,080 per month (at $1.50 per hour).
Outside peak hours, we can scale down the deployment to 0 nodes, and spin it up whenever necessary.
The issue with this GPU really comes down to one thing: memory bandwith. The 4090 has a memory bandwidth of ~1 TB/s, which is evidently not enough to achieve a low enough latency for code completion. Also, you only get around 200-300 TFLOPS at bf16.
Long story short – this GPU was not built for ML workloads, it's a gaming GPU. Let's try something more serious.
More VRAM: 7B model on RTX 6000 Ada (48 GB)
Same model as before, but we upgrade to a 48 GB GPU. The results:
$ echo "POST http://127.0.0.1:8000/v1/completions" | vegeta attack -rate=32 -duration=5s -body req.json -header 'Content-Type: application/json' | tee results.32.bin | vegeta report
Requests [total, rate, throughput] 160, 32.20, 20.47
Duration [total, attack, wait] 7.815s, 4.969s, 2.846s
Latencies [min, mean, 50, 90, 95, 99, max] 2.846s, 3.225s, 3.259s, 3.376s, 3.394s, 3.46s, 3.464s
Bytes In [total, mean] 143908, 899.42
Bytes Out [total, mean] 466240, 2914.00
Success [ratio] 100.00%
Status Codes [code:count] 200:160A p99 latency of 3.5s - not great, not terrible. But definitely much better than the 4090. If we use two instances, the load can be shared between the two, reducing latency down to ~2.5s.
Our system requirements with this setup:
- Hardware: 2x RTX 6000 Ada
- Cost: $1,152 per month (at $1.60 per hour)
But a latency of 2.5s still won't cut it – we need something more capable.
More Bandwidth and Compute: 7B model on H100 SXM (80 GB)
The primary bottleneck in inference is memory bandwidth – the number of bytes that can be transferred from the GPUs high-bandwidth memory to the on-chip registers and L1/L2 caches.
So we'll try our load test with a top-of-the-line GPU, the H100 SXM, with 3 TB/s of bandwidth:
$ echo "POST http://127.0.0.1:18000/v1/completions" | vegeta attack -rate=32 -duration=5s -body req.json -header 'Content-Type: application/json' | tee results.32.bin | vegeta report
Requests [total, rate, throughput] 160, 32.21, 26.73
Duration [total, attack, wait] 5.986s, 4.968s, 1.018s
Latencies [min, mean, 50, 90, 95, 99, max] 1.018s, 1.156s, 1.152s, 1.163s, 1.376s, 1.433s, 1.457s
Bytes In [total, mean] 144703, 904.39
Bytes Out [total, mean] 466240, 2914.00
Success [ratio] 100.00%
Status Codes [code:count] 200:160
We're now down to a p99 latency of 1.4s – perfectly serviceable. At lower workload, we get even better results, the lower bound of the latency hovers just below 1s:
$ echo "POST http://127.0.0.1:18000/v1/completions" | vegeta attack -rate=8 -duration=5s -body req.json -header 'Content-Type: application/json' | tee results.8.bin | vegeta report
Requests [total, rate, throughput] 40, 8.20, 6.83
Duration [total, attack, wait] 5.853s, 4.875s, 977.121ms
Latencies [min, mean, 50, 90, 95, 99, max] 977.121ms, 992.171ms, 993.101ms, 996.717ms, 997.554ms, 998.414ms, 998.414ms
Bytes In [total, mean] 36178, 904.45
Bytes Out [total, mean] 116560, 2914.00
Success [ratio] 100.00%
Status Codes [code:count] 200:40
Error Set:
$ echo "POST http://127.0.0.1:18000/v1/completions" | vegeta attack -rate=1 -duration=5s -body req.json -header 'Content-Type: application/json' | tee results.1.bin | vegeta report
Requests [total, rate, throughput] 5, 1.25, 1.01
Duration [total, attack, wait] 4.961s, 4.001s, 960.22ms
Latencies [min, mean, 50, 90, 95, 99, max] 960.22ms, 961.714ms, 960.893ms, 964.794ms, 964.794ms, 964.794ms, 964.794ms
Bytes In [total, mean] 4460, 892.00
Bytes Out [total, mean] 14570, 2914.00
Success [ratio] 100.00%
Status Codes [code:count] 200:5
So all you need to run this workload is:
- Hardware: A single H100 SXM
- Cost: $1,648 per month (at $2.29 per hour with 1 year commitment).
Big Model: 32B Model on H100 SXM (80 GB)
Maybe 7B doesn't cut it for you. You want serious horsepower, you want a state-of-the-art coding model that beats most other models on coding benchmarks.
Well, we have Qwen 2.5 Coder 32B:
// 32 req/sec
Requests [total, rate, throughput] 160, 32.20, 17.54
Duration [total, attack, wait] 9.124s, 4.969s, 4.155s
Latencies [min, mean, 50, 90, 95, 99, max] 4.155s, 4.456s, 4.465s, 4.529s, 4.607s, 4.713s, 4.745s
Bytes In [total, mean] 146108, 913.17
Bytes Out [total, mean] 466400, 2915.00
Success [ratio] 100.00%
Status Codes [code:count] 200:160
Error Set:
// 8 req/sec
Requests [total, rate, throughput] 40, 8.21, 4.71
Duration [total, attack, wait] 8.495s, 4.875s, 3.621s
Latencies [min, mean, 50, 90, 95, 99, max] 3.607s, 3.751s, 3.762s, 3.838s, 3.845s, 3.85s, 3.85s
Bytes In [total, mean] 36760, 919.00
Bytes Out [total, mean] 116600, 2915.00
Success [ratio] 100.00%
Status Codes [code:count] 200:40
// 1 req/sec
Requests [total, rate, throughput] 5, 1.25, 0.67
Duration [total, attack, wait] 7.408s, 4s, 3.407s
Latencies [min, mean, 50, 90, 95, 99, max] 3.391s, 3.407s, 3.405s, 3.433s, 3.433s, 3.433s, 3.433s
Bytes In [total, mean] 4643, 928.60
Bytes Out [total, mean] 14575, 2915.00
Success [ratio] 100.00%
Status Codes [code:count] 200:5
The lower-bound latency is 3.4s, which could work. But realistically, you don't want to use such a heavy model for code completion.
What you do want to use this model as, is a fairly competent chat model. With streaming responses, you can get really good UX with these models for chat – full-response latency isn't as much of a concern. Fine-tuned to your internal code and documentation, running on your own infra for under $600 a month. In comparison, this much money will only get you 15 GitHub Copilot Enterprise licenses. Unlimited requests per month, where Copilot caps it to a 1000 "premium" requests.
Conclusion
To summarize: the H100 is a compelling option to self-host your own coding LLM, for a reasonable cost.
Deploying your own LLM for coding is very much feasible, and offers you a powerful way to gain privacy, customization abilities and reduce costs. And it isn't as scary as it seems – there are several projects that aim to make self-hosting as simple as spinning up a container in your own private cloud, e.g., TabbyML.