What's Under Copilot's Hood?
This is a very quick post on GitHub Copilot's constructs the prompt when serving code completions.
Since Copilot isn't open source, the only way to figure this out is by dumping the request/response payloads and examining them. I used mitmproxy to log requests made by Copilot during the course of coding in VS Code.
Here's a sample request:
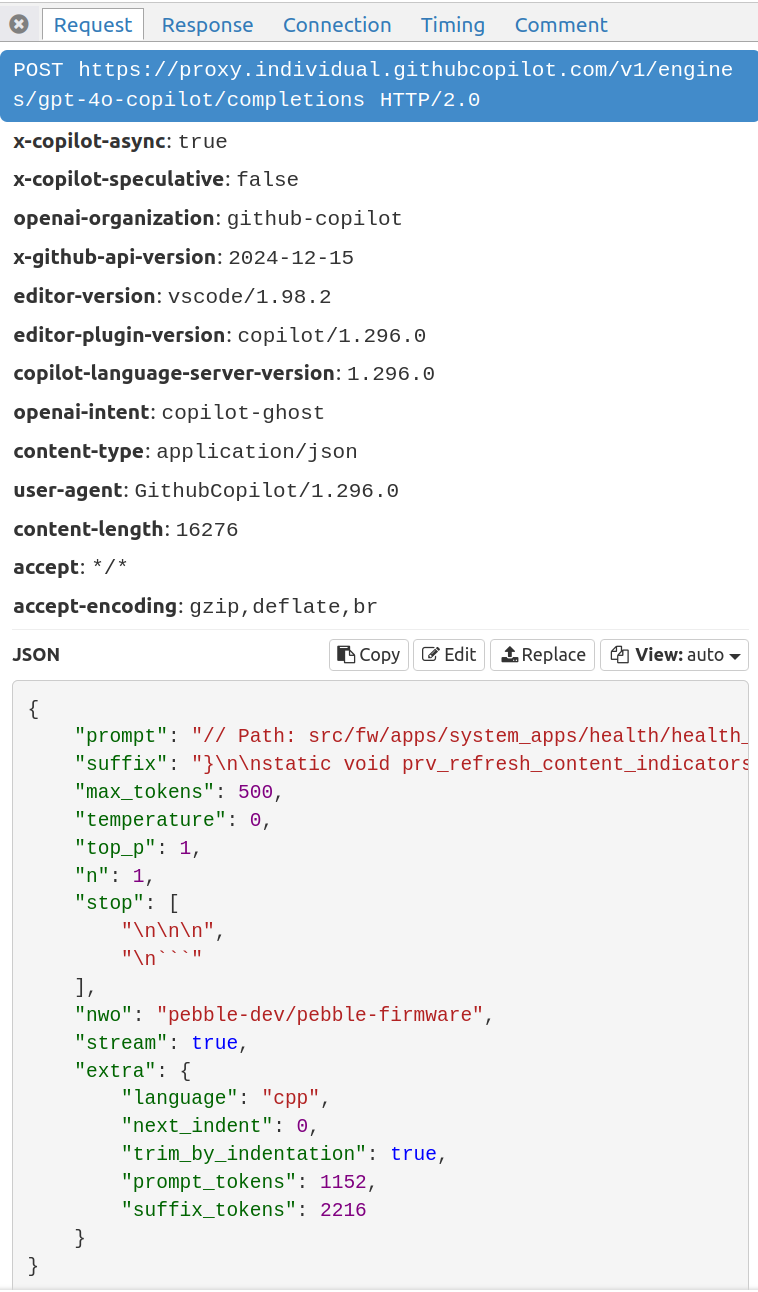
Full sample request/response: https://gist.github.com/prvnsmpth/ad922a0e887376e44fcd9c62c8c287ad
A few observations:
- The prompt (the prefix) and suffix total 3,368 tokens. I noticed some other requests with as many as 6,500 tokens. Not sure where the max lies, but I doubt it's much more than that.
- The output tokens are limited to 500. Any higher than that, and latency will be too high.
- There's a
x-copilot-speculativeheader – which all but confirms that Copilot uses speculative decoding. It's set to false here though, not clear in what scenarios it will be enabled. It's probably being A/B tested. - We have
stream: true, although it's not clear why. Suggestions shown in VS Code are not updated in real-time, they are shown only after the entire response is received.
Now on to the most important part, the prompt itself.
Building the Prompt
Copilot appears to pulls in context largely from other open files in the editor.
❯ cat /tmp/req.json | jq -r '.prompt' | grep -A 3 -n 'Compare'
2:// Compare this snippet from src/fw/console/dbgserial_input.h:
3-// /*
4-// * Copyright 2024 Google LLC
5-// *
--
38:// Compare this snippet from src/fw/console/control_protocol.c:
39-// mutex_lock(this->state->lock);
40-// LinkState state = this->state->link_state;
41-// mutex_unlock(this->state->lock);
--
99:// Compare this snippet from src/fw/console/control_protocol.c:
100-// this->on_this_layer_down(this);
101-// }
102-//
--
160:// Compare this snippet from src/fw/syscall/app_pp_syscalls.c:
161-// * limitations under the License.
162-// */
163-//
--
220:// Compare this snippet from src/fw/console/control_protocol.c:
221-// .next_terminate_id = 0,
222-// };
223-// }
--
281:// Compare this snippet from src/fw/console/control_protocol.c:
282-// packet->identifier = this->state->next_code_reject_id++;
283-// size_t body_len = MIN(ntoh16(bad_packet->length),
284-// pulse_link_max_send_size() - LCP_HEADER_LEN);
These files where open in the editor at the time of capturing the request:
src/fw/apps/system_apps/health/health_card_view.c (editing)
src/fw/console/control_protocol.c
src/fw/syscall/app_pp_syscalls.c:
src/fw/console/dbgserial_input.h
Copilot pulls in relevant snippets from open files. From the line numbers above, we can see that each snippet is about 60 lines long. I suspect Copilot uses some sort of embedding index lookup to determine which portions of the code are most relevant.
Notably, it appears that Copilot does not invoke the language server to fetch relevant definitions. This is a bit surprising, because when you are, say, invoking completions when filling in function arguments, e.g.,
my_very_important_func(|)
// ^ cursor hereYour prompt better have the function definition in it, because otherwise there's a good chance your LLM will get it wrong.
I suspect that querying the language server might be too expensive an operation to invoke on every single completion request, and perhaps that is why the Copilot team decided against it. It would also mean that Copilot's performance would now be tied to the performance of the language server, which varies widely, depending on language.
Speaking of performance, that's another aspect that requires some discussion.
Latency
I've been using Copilot for a long time now, and I would often run into the following scenario: I'd open up my editor (VS Code or IntelliJ), open up a file and start writing, and then pause; waiting for Copilot to complete my thought.
But I would often see nothing, save for the little Copilot icon in the bottom right spin around for a bit, and then disappear. I'd always assumed that this was some sort of timeout, and today, peeking into the request/response confirmed it.
You see, on a fresh request (no caching), Copilot often sends a large amount of context – sometimes totaling 6.5k tokens. That's a lot of tokens to process, and it invariably ends up taking at least 1-2 seconds. That is enough to delay the response past the timeout set on the client-side (which I think is about 1 sec).
Quick detour into LLM inference, there are two phases: (1) prompt processing, and (2) output token generation. When an LLM inference server receives a prompt, it runs it through the transformer model in a single forward pass, computing the key and value projection tensors and caching them. Output token generation is then much faster, because the previous keys and values are cached. (See The Animated Transformer for a primer.)
This means that subsequent requests made by Copilot are much faster, depending only on the amount of time taken to generate the output tokens.
That's all for now.
In a future post, I might look into the request payloads in other types of assistance that Copilot provides – next edit suggestions, chat responses, applying edits, etc. Stay tuned!